当サイトはアフィリエイト広告経由のサービスを含みます
当サイトはアフィリエイト広告経由のサービスを含みます BeautifulSoup4でデータが取得できないときにはSeleniumと併せて使うことで解決
更新日:2022年04月23日BeautifulSoup4でデータがうまく取得できないことありませんか?
そんなときには、Seleniumと併せて使ってみるのがおすすめです。
seleniumとBeautifulSoup4を併せたスクレイピング方法はこちら
BeautifulSoup4でデータが取得できない原因は?
BeautifulSoup4はHTMLやXMLから必要なデータを抽出するためのライブラリです。
高速で使い勝手もいいのですが、JSによる値の変化やログインやボタンクリックなどの動きが必要になる場合には、必要なデータを取得できません。
Webスクレイピングで使用する場合には、requestしたURLで取得できるHTMLに対して、抽出処理が適用されるため、JSによるフィルターや2ページ目といった処理にも対応できないのです。
Seleniumを使えばBeautifulSoup4だけでは取得できなかったデータの取得も可能
一方、SeleniumはWebブラウザの操作を自動化するためのテストフレームワークです。
こちらはBeautifulSoupと異なり、Webブラウザ上での動きをテストするためのツールになるため、JSによる値の変化やログイン後のページへのアクセスが可能です。
Seleniumで取得したいデータが表示されたURLを取得し、BeautifulSoup4使ってWebスクレイピングを利用することで、これまで取得できなかったデータを取得できることが期待できます。
具体的に見ていきましょう。
下記ページにテストページを用意しています。
テストページ
こちらのページではリスト形式でデータが表示されており、削除ボタンを押すことで、リストのデータを1つ削除できるようになっています。
まずBeautifulSoup4のみでリストのデータを取得してみます。
BeautifulSoup4での取得コードは下記の通りです。※Google Colabで実装してい
!pip freeze | grep request
!pip freeze | grep beautiful
import requests
r = requests.get('https://freelancemate.me/test')
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'lxml')
lis = soup.find_all('li')
for li in lis:
print(li)
リストの値を取得してHTMLとして吐き出しています。取得後のデータは下記の通りです。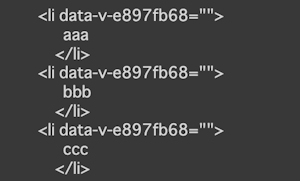
BeautifulSoup4の場合には、JSの操作などができません。そのため、リストのデータは最初にレンダリングされる項目のみが取得対象となります。
次に、Seleniumと組み合わせて、リストのデータを変更した形でデータ取得を行います。
先ほど同様に、Google Colabで下記の通りに記載を行います。
!pip install selenium
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
#webdriverに関するオプション設定
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
from selenium.webdriver.common.by import By
driver = webdriver.Chrome('chromedriver',options=options)
driver.get("https://freelancemate.me/test")
#削除ボタンの検索
button = driver.find_element(By.TAG_NAME, "button")
#削除ボタンのクリック
button.click()
#ソースのエンコード
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
lis = soup.find_all("li")
for li in lis:
print(li)
上記コード実行後の取得データは下記の通りです。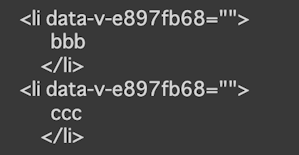
Seleniumで値を削除した後のデータの取得ができています。
このように、Seleniumを使うことでこれまで取得できなかったデータを取得できるようになります。
ただ、Seleniumは少々重たいので、bs4で完結するページの場合には、bs4で対処する方がベターです。
Webスクレイピングをする際には注意を
Webスクレイピングは法律で禁止されている行為ではありませんが、短時間の高頻度アクセスはサーバーをダウンさせる事態を招く可能性があります。
スクレイピングを実施する際はマナーを守り、自己責任で実施をお願いいたします。
また、Webサイトによっては、利用規約やプライバシーポリシーなどでスクレイピングを禁止しているサイトもありますので、Webサイトのルールに従ってください。